
| |
|
|
| |
News and information
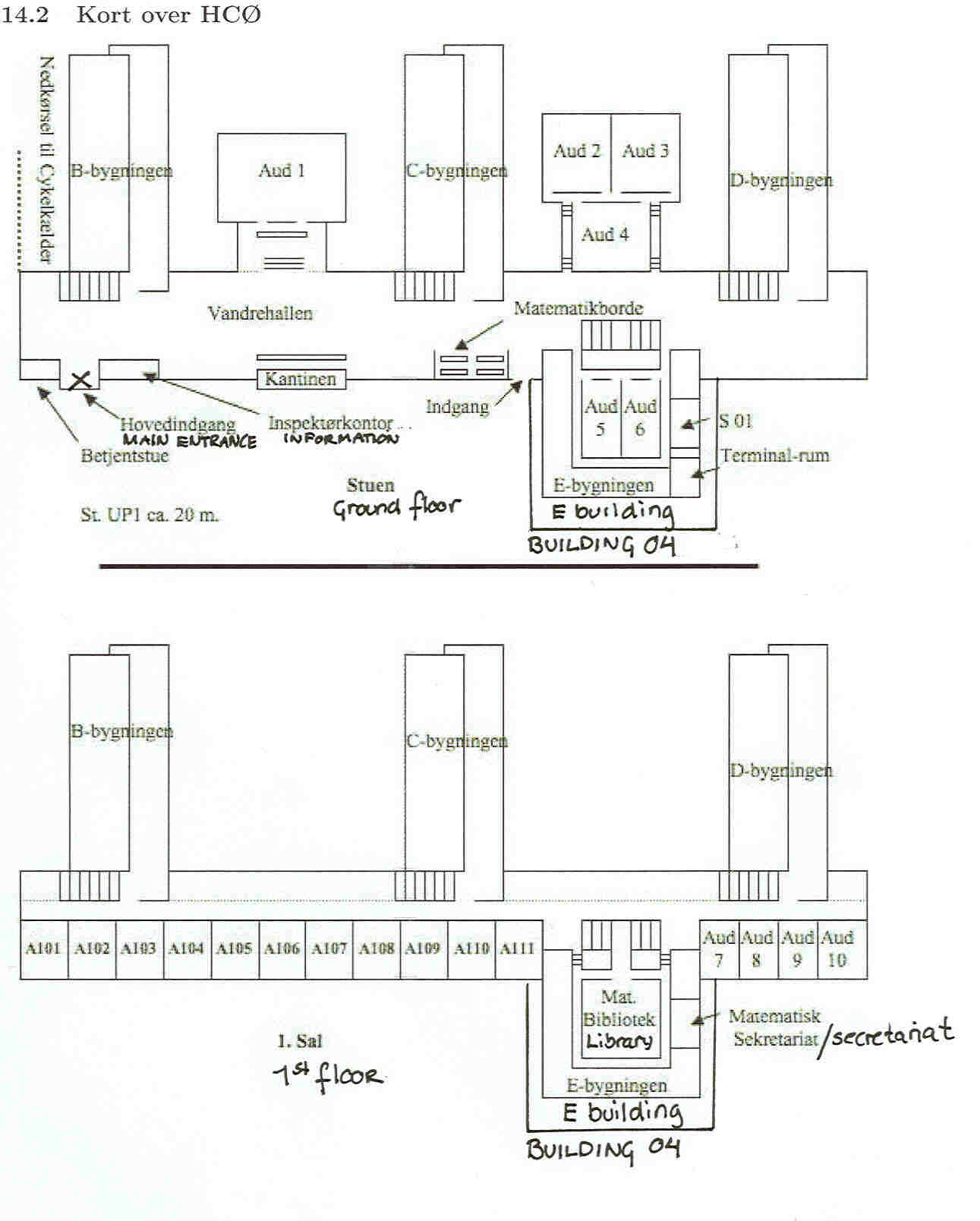
Time and PlaceThe course takes place from April 20 to June 19, 2009. There are lectures and exercises in week 18 (April 27 - May 1) and week 22 (May 25 - May 31) at the University of Copenhagen. For the remaining weeks there are preparation, homework exercises and individual projects.The lectures and exercises will take place at Auditorium 4, HCØ University of Copenhagen Universitetsparken 5 DK-2200 Copenhagen Ø Course DescriptionRemark: The primary literature for the course is the book:Hastie, T, Tibshirani, R, and Friedman, Jerome. The Elements of Statistical Learning. Data mining, inference, and prediction. Springer, 2nd ed., 2009. The book has just come out in a seconde edition, which we will use. Since I have not had the book in my hand yet the precise content of the course may be subject to minor changes depending on the exact nature of the revision of this second edition. The main topic of this course is models and methods suitable for analyzing high dimensional data where there are typically many features compared to replications. This is a typical situation met in bioinformatics and exemplified by gene expression data, where we analyze experiments with thousands of parallel measurements and few replications. The course focuses on supervised learning where typical approaches to high-dimensional data analysis involve flexible models combined with shrinkage or regularization algorithms, such as ridge or Lasso regression perhaps combined with basis expansion techniques such as spline regression and smoothing splines. Also non-generative models such as classification and regression trees are found useful for prediction purposes. In the course we start with linear methods for regression and classification and move on to four more advanced topics:
Access to good statistical software is paramount. Therefore we will illustrate the use of the models throughout the course with methods implemented in R, and the course will train the participants in using R and Bioconductor software for the analysis of expression data. CreditParticipants who pass the final project will receive a certificate of participation.PrerequisitesThe participants are expected to know the theory for the multivariate normal distribution, ordinary multiple regression and linear normal models, and in particular the linear algebra associated with these models. Participants also need to be confident with random variables, probability measures, expectations and conditional expectations though the course by no means will focus on a formal, measure theoretic approach, the book uses e.g. expectations and conditional expectations and their computational rules.Participants also need some prior experience with R and an interest in practical applications to biological questions. You need to know about the fundamental data structures such as vectors, lists and data frames and the fundamental functions such as lm for linear models and it is probably also necessary to know how to produce graphics. The participants are also expected to bring their own laptop for the exercises. We require that all participants prior to the course install the latest version of R and the latest version of Bioconductor (which releases will be announced on this web page when settled). As it looks right now R version 2.9.0 is used with the additional packages below. We will not use any particular bioconductor packages this week. Additional packages may be added for the last part of the week and for the second week.
ProgramProgram:April 20 -24: Preparation home.
Below you find information on which sections in the book we cover and when. There are also a number of practical exercises announced. They will be made available during the course. They will consist mostly of small R exercises for training the use of R on various pratical problems. Usually you will be given approximately 30-45 minutes to solve the exercise on your own computer. Solutions will be provided.
Classification of individuals based on "genetic fingerprint". DATA Hand-in deadline for the assignment is May 22.
Microarray classification DATA *The two fridays are reserved for "Individual work", which means that you can work on some of the exercises from the week. I will be available for questions during the day. RegistrationTo register for the course send an email to Niels Richard Hansen. Dealine for registration is April 1. The number of participants at the course is limited to 28 students. In case of overbooking students from the universities participating in the BCM-network will be given priority.Miscellaneous
MaterialPrimary literature for the course is
See also the web page for the book The Elements of Statistical Learning for links to data, R resources, errata, etc. During the course you will do the following 6 theoretical and 9 practical exercise.
The above theoretical exercises will be made available from the course start. Additional exercises from the book will be pointed out along the way. For additional reading we recommend the books:
Directions and accommodationPlease find information on directions and accommodation on our website. Note that we have no possibility to give financial support for participants. |
|



{kind=link}